


Odkrycia Uniwersytetu Rice ujawniają, że powtarzalne uczenie się danych syntetycznych może prowadzić do „zaburzenia autofagii modelowej”, pogarszającego jakość generatywnych modeli sztucznej inteligencji. Ciągłe poleganie na danych syntetycznych bez świeżych danych wejściowych może skazać przyszłe modele sztucznej inteligencji na nieefektywność i zmniejszoną różnorodność.
Generatywny sztuczna inteligencja Modele (AI), takie jak GPT-4o OpenAI lub Stable Diffusion firmy Stability AI, doskonale radzą sobie z tworzeniem nowego tekstu, kodu, obrazów i filmów. Jednak uczenie tych modeli wymaga ogromnych ilości danych, a programiści już zmagają się z ograniczeniami podaży i wkrótce mogą całkowicie wyczerpać zasoby szkoleniowe.
Ze względu na niedobór danych wykorzystywanie danych syntetycznych do szkolenia przyszłych generacji modeli sztucznej inteligencji może wydawać się kuszącą opcją dla dużych technologii z wielu powodów. Dane syntetyzowane przez sztuczną inteligencję są tańsze niż dane ze świata rzeczywistego i praktycznie nieograniczone pod względem podaży, stwarzają mniej zagrożeń dla prywatności (jak w przypadku danych medycznych), a w niektórych przypadkach dane syntetyczne mogą nawet poprawić wydajność sztucznej inteligencji.
Jednak niedawne prace grupy Digital Signal Processing na Uniwersytecie Rice wykazały, że dieta oparta na danych syntetycznych może mieć znaczący negatywny wpływ na przyszłe iteracje generatywnych modeli sztucznej inteligencji.

Zagrożenia związane z treningiem autofagicznym
„Problemy pojawiają się, gdy to syntetyczne uczenie danych jest nieuchronnie powtarzane, tworząc rodzaj pętli sprzężenia zwrotnego ⎯ tego, co nazywamy pętlą autofagiczną lub „samokonsumującą się”” – powiedział Richard Baraniuk, profesor elektryki i elektryki w firmie Rice C. Sidney Burrus Inżynieria komputerowa. „Nasza grupa intensywnie pracowała nad takimi pętlami sprzężenia zwrotnego, a zła wiadomość jest taka, że nawet po kilku pokoleniach takiego szkolenia nowe modele mogą ulec nieodwracalnemu uszkodzeniu. Niektórzy nazywają to „upadkiem modelu” ⎯ ostatnio przez kolegów w tej dziedzinie w kontekście dużych modeli językowych (LLM). Uważamy jednak, że termin „modelowe zaburzenie autofagii” (MAD) jest bardziej trafny, przez analogię do choroba szalonych krów.”
Choroba szalonych krów to śmiertelna choroba neurodegeneracyjna, która dotyka krowy i ma ludzki odpowiednik, spowodowana spożyciem zakażonego mięsa. A wybuch poważnej epidemii XX wieku zwrócili uwagę na fakt, że choroba szalonych krów szerzyła się w wyniku karmienia krów przetworzonymi resztkami zamordowanych rówieśników ⎯ stąd termin „autofagia” z greckiego auto-, co oznacza „samodzielność” ”,” i phagy ⎯ „jeść”.
„Nasze ustalenia dotyczące MADness przedstawiliśmy w artykule zaprezentowanym w maju na Międzynarodowej Konferencji na temat reprezentacji uczenia się (ICLR)” – powiedział Baraniuk.
Badanie zatytułowane „Self-Consuming Generative Models Go MAD” jest pierwszą recenzowaną pracą na temat autofagii sztucznej inteligencji i skupia się na generatywnych modelach obrazu, takich jak popularne DALL·E 3, Midjourney i Stable Diffusion.
Wpływ pętli treningowych na modele AI
„Zdecydowaliśmy się pracować nad wizualnymi modelami sztucznej inteligencji, aby lepiej uwypuklić wady treningu autofagicznego, ale w przypadku LLM występują te same problemy z korupcją szalonych krów, jak zauważyły inne grupy” – powiedział Baraniuk.
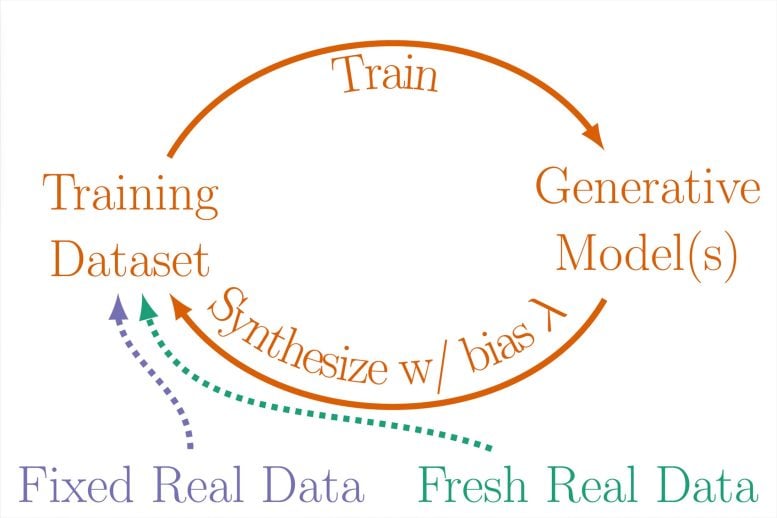
Internet jest zwykle źródłem zbiorów danych szkoleniowych generatywnych modeli sztucznej inteligencji, zatem w miarę rozprzestrzeniania się danych syntetycznych w Internecie z każdą nową generacją modelu prawdopodobnie będą pojawiać się samo zużywające się pętle. Aby uzyskać wgląd w różne scenariusze tego, jak to może się rozegrać, Baraniuk i jego zespół zbadali trzy odmiany samo zużywających się pętli treningowych, zaprojektowanych w celu zapewnienia realistycznej reprezentacji łączenia danych rzeczywistych i syntetycznych w zbiory danych szkoleniowych dla modeli generatywnych:
- w pełni syntetyczna pętla ⎯ Kolejne generacje modelu generatywnego karmiono w pełni syntetyczną dietą, na podstawie której pobrano próbki z wyników poprzednich pokoleń.
- syntetyczna pętla wzmacniająca ⎯ Zbiór danych szkoleniowych dla każdej generacji modelu zawierał kombinację danych syntetycznych pobranych z poprzednich generacji i ustalony zestaw rzeczywistych danych szkoleniowych.
- pętla świeżych danych ⎯ Każda generacja modelu jest trenowana na mieszance danych syntetycznych z poprzednich generacji i świeżym zestawie rzeczywistych danych uczących.
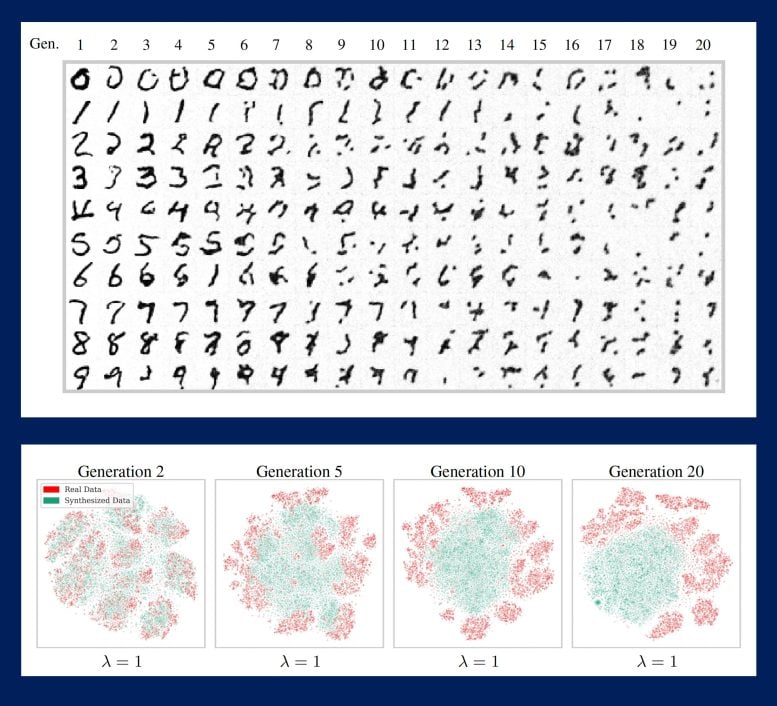
Progresywne iteracje pętli ujawniły, że z biegiem czasu i przy braku wystarczających świeżych danych rzeczywistych modele będą generować coraz bardziej zniekształcone wyniki, którym będzie brakować jakości lub różnorodności albo obu. Innymi słowy, im więcej świeżych danych, tym zdrowsza sztuczna inteligencja.
Konsekwencje i przyszłość generatywnej sztucznej inteligencji
Bezpośrednie porównania zbiorów danych obrazów powstałych w wyniku kolejnych generacji modelu dają niesamowity obraz potencjalnej przyszłości sztucznej inteligencji. Zbiory danych składające się z ludzkich twarzy są coraz bardziej pokryte siatkowatymi bliznami ⎯, co autorzy nazywają „artefaktami generatywnymi”, ⎯ lub coraz bardziej przypominają tę samą osobę. Zbiory danych składające się z liczb przekształcają się w nieczytelne bazgroły.
„Nasze analizy teoretyczne i empiryczne umożliwiły nam ekstrapolację tego, co może się wydarzyć, gdy modele generatywne staną się wszechobecne, oraz uczenie przyszłych modeli w pętli samokonsumujących” – powiedział Baraniuk. „Niektóre konsekwencje są jasne: bez wystarczającej ilości świeżych, rzeczywistych danych przyszłe modele generatywne są skazane na MAD”.
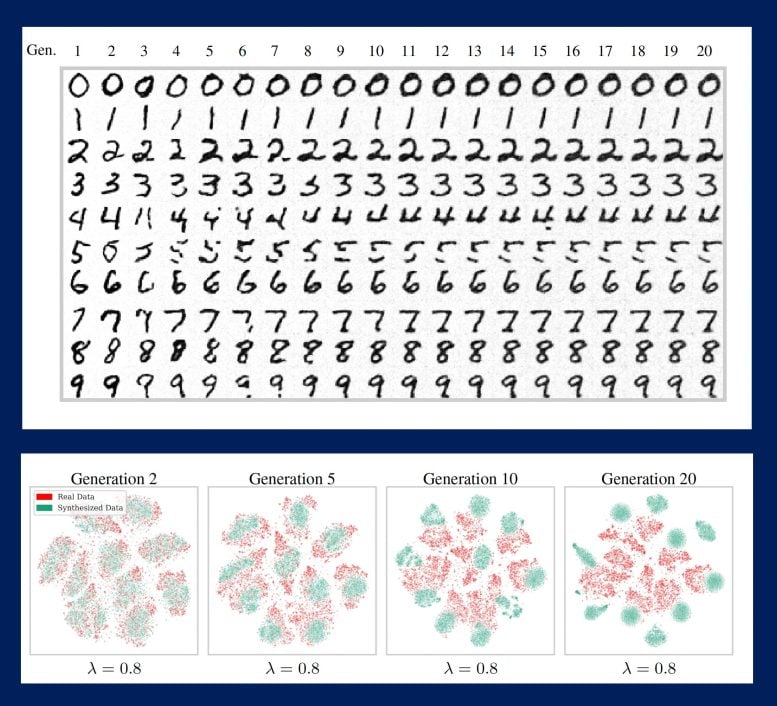
Aby uczynić te symulacje jeszcze bardziej realistycznymi, badacze wprowadzili parametr błędu próbkowania, aby uwzględnić „wybieranie wiśni” ⎯ tendencję użytkowników do przedkładania jakości danych nad różnorodność, tj. kompromisu w zakresie typów obrazów i tekstów w zbiorze danych obrazy lub teksty, które wyglądają lub brzmią dobrze. Zachętą do selekcji jest to, że jakość danych zostaje zachowana w większej liczbie iteracji modelu, ale dzieje się to kosztem jeszcze bardziej gwałtownego spadku różnorodności.
„Jeden ze scenariuszy zagłady jest taki, że jeśli MAD pozostanie bez kontroli przez wiele pokoleń, może zatruć jakość danych i różnorodność całego Internetu” – powiedział Baraniuk. „Poza tym wydaje się nieuniknione, że autofagia sztucznej inteligencji wyniknie z autofagii sztucznej inteligencji, której jeszcze nie widać, nawet w najbliższej przyszłości”.

Odniesienie: „Samowystarczalne modele generacyjne popadają w szaleństwo” autorzy: Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Babaei, Daniel LeJeune, Ali Siahkoohi i Richard Baraniuk, 8 maja 2024 r., Międzynarodowa konferencja na temat reprezentacji uczenia się (ICLR), 2024.
Oprócz Baraniuka autorami badania są m.in. dr Rice. studenci Sina Alemohammad; Josue Casco-Rodriguez; Ahmed Imtiaz Humayun; Hossein Babaei; Doktor ryżu absolwent Lorenzo Luzi; Doktor ryżu absolwent i obecny doktorant na Uniwersytecie Stanforda Daniel LeJeune; oraz stypendysta podoktorski Simons Ali Siahkoohi.
Badania były wspierane przez Narodową Fundację Nauki, Biuro Badań Marynarki Wojennej, Biuro Badań Naukowych Sił Powietrznych i Departament Energii.



{kind=link}